G.O.S.S.I.P 阅读推荐 2024-11-27 又一个内核内存安全漏洞猎手
全世界的计算机安全课程(甚至稍微深入一点的C语言课程)大概都会给学生看这么一幅图:
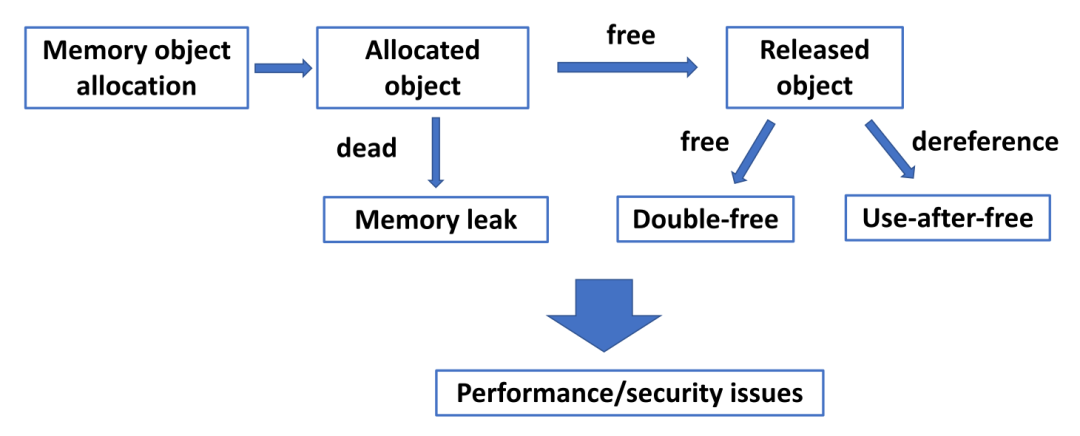
然后,大概就和学数学一样,老师教了一个非常简单的原理,接下来要你证明的题目一个也不会(手动狗头)。虽然上面这幅图清晰直观地展示了(动态)内存安全问题的本质,在真实代码中,我们往往很难去捕捉相关的问题,很多代码甚至在被使用超过数十年的时间后依然还会存在相关的bug和漏洞,这是为什么呢?
答案是:现实世界的代码远比你想象中更复杂,就像很多事情并不是非黑即白一样,除非你只想去找到那种最最简单的问题形式,否则你就得要去考虑很多很多细节。在我们过去的推荐中,经常提到一类安全分析工作,它们彷佛是在研究某种“代码心理学”,也就是考虑程序员怎么犯错误,并通过这种思路去捕捉代码中的问题,今天我们要为大家介绍的USENIX Security 2024论文Detecting Kernel Memory Bugs through Inconsistent Memory Management Intention Inferences就是这类工作的又一典型代表:

在这篇论文中,作者总结了一个叫做inconsistent memory management intentions(IMMI)的概念,理解了这个概念,你就理解了本文最关键的思想。让我们先回到最基本的(Linux内核)内存管理实现中去,看两个基本的编程策略。在现实中,内存分配需要考虑的out of memory的情况,如果没有分配到需要的资源,就需要进入到异常处理分支,但是谁来负责这个收尾工作?我们观察到通常是有两种策略:一种叫做callee-based management,也就是在(被调用的)内存管理函数内部进行善后工作;一种叫做caller-based management,这种情况下内存管理函数只返回一个信息说“我失败了”,其它事情交给调用者去处理。下面的两份代码示例可以让我们更好理解这两种情况:


好,那究竟什么是IMMI呢?很简单,上面这两种策略,没有人规定说一定要用哪种,更可怕的是,caller和callee函数之间缺少沟通(也就是所谓的inconsistent intention),要么两者都不负责(都假设对方会去执行处理任务),要么两者都抢着负责,结果要么就是导致内存泄露(大家都不负责),要么就产生了Double Free或者UAF问题(大家都抢着负责)。实际上,如果caller和callee不是同一个开发者设计的(或者是同一个开发者设计,但可能是开发了其中一个函数后很久再去开发另一个),这种出错的概率就更大了。
如果能够有效地追踪上面提到的这些IMMI,那么我们可以期待找到许多新问题,而且这个方法的一个非常有吸引力的特点是它相对于其他的分析工作来说开销是比较小的,因为只需要考虑内存管理函数和调用者之间的关系。但是要实现整套分析,里面需要解决的问题还是蛮多的,作者设计了如下的工作流程,让我们去解读一下:
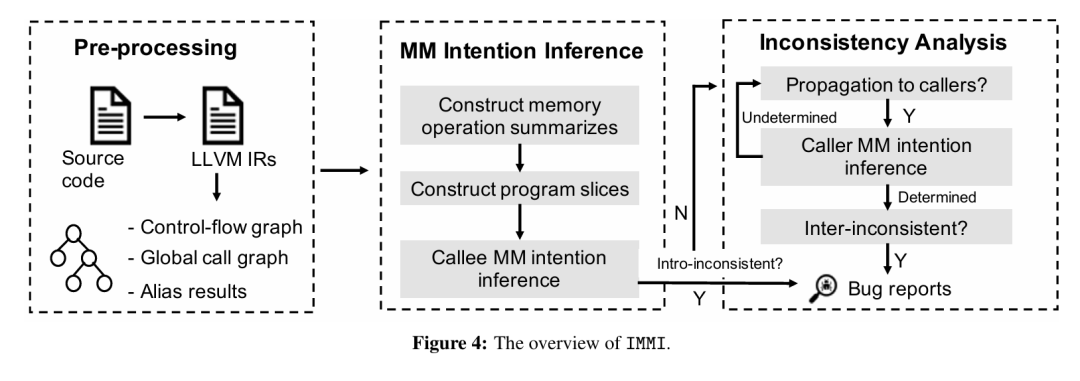
上面这个流程的第一步,如果大家参加过2023年的Let’s GoSSIP暑期学校,听过卢康杰老师的课程,就肯定不会陌生。这里就是很标准的把(Linux内核)代码编译成LLVM IR(bitcode)形式并且进行一些基本的分析(比如alias analysis)的过程,我们就略过。整个分析过程最关键的是上图的中间部分(MM Intention Inference),在这一步中,作者首先要给内存管理操作进行总结(summarization),这个和G.O.S.S.I.P在2022年的工作Goshawk是类似的,不过本文作者觉得Goshawk提出的那个MOS概念都太复杂了,他们用了一个更加简单的总结方式(下图所示是一个实例),也就是从最基本的一些内存管理函数(kfree这种)出发,然后逐步去寻找更上层的封装函数。仔细看一下就会发现,这个总结方式关注的是一个特定的内存管理函数(MM function)内部怎么去处理(分配和释放)内存对象的,没有把它和函数参数关联起来,这个可能是它和Goshawk工作里面的MOS概念的一个大的区别。具体的实现细节,大家可以看论文的4.2章。
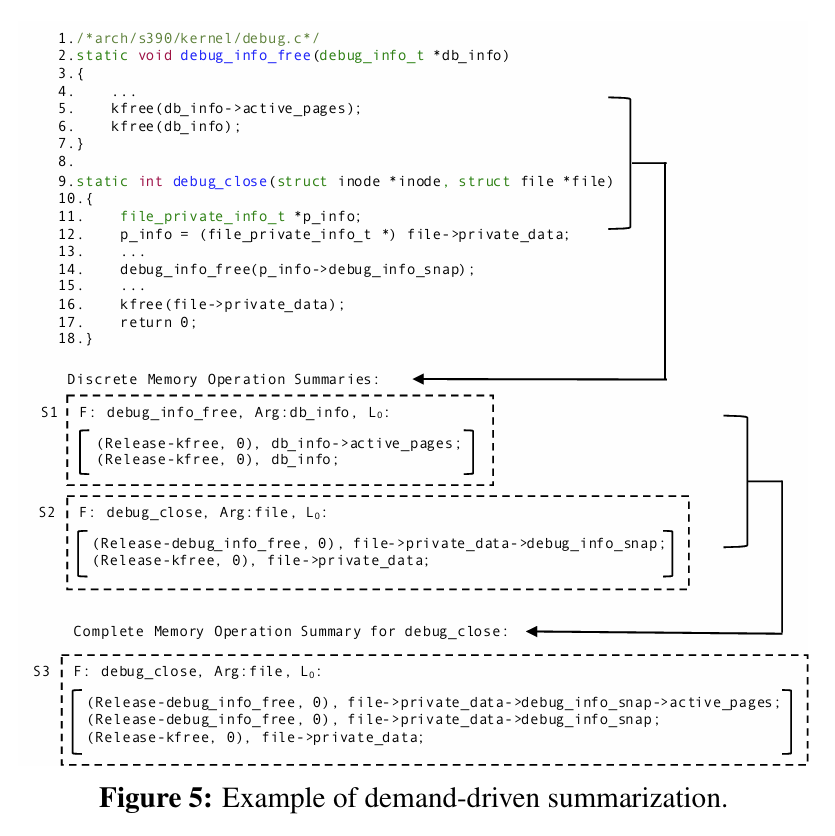
在总结了函数是如何管理内存对象之后,本文的工作进一步去做了代码切片分析,只关注和内存对象相关的代码,减少分析的工作量。当然,论文中很重要的一个方面,是识别到底一个函数是callee-based management还是caller-based management风格。作者认为,下面图中展示的这类函数,它们的管理策略或者是callee-based management和caller-based management中的一种,或者在函数内部多个错误处理分支中产生了不一致。如果是后者,那么直接就可以报bug了,如果是前者,那么继续分析。

要做到这一点,作者请出来了现在的当红炸子鸡——LLM来帮忙,因为可以从上面的代码中看到,文本里面就有很多的信息。作者设计了如下的prompt来教LLM怎么去识别(感觉Prompt工程里面最好笑的是一开始要告诉LLM它是什么身份):

只要完成了上述的分析,寻找bug的基本要素都齐备了,最后就只需要进行关联分析——把caller和callee关联起来检查有没有IMMI的情况存在。这个分析的最大特色之一就是它的运行效率非常高,对整个内核的分析时间竟然只要不到40分钟就搞定了(要知道分析的机器也就只有一颗Xeon Silver 4316 CPU)

实验分析表明,使用LLM的主要好处是去除了很多的误报,整个分析最后报告了123个bug,其中确认了80个bug,包括57个memory leak的情况、16个double-free bug、6个UAF bug和一个null-pointer
dereference bug,结果看上去很漂亮。
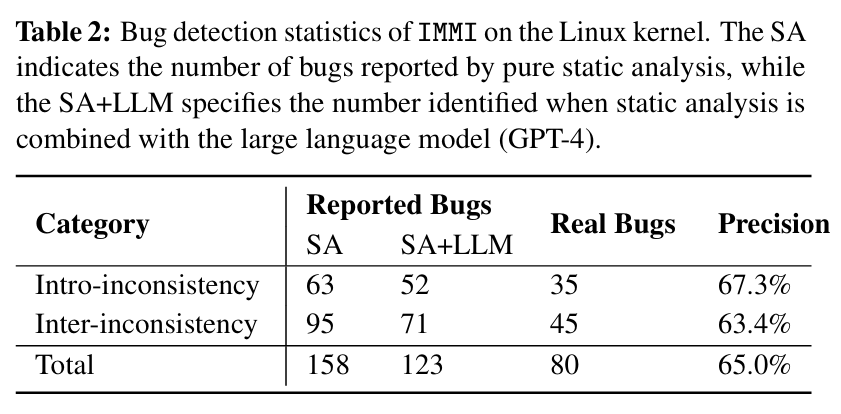
现在大家写论文,不光要比自己的工具,也要比比用哪个大模型更好,毕竟是要往里面真金白银充钱的!
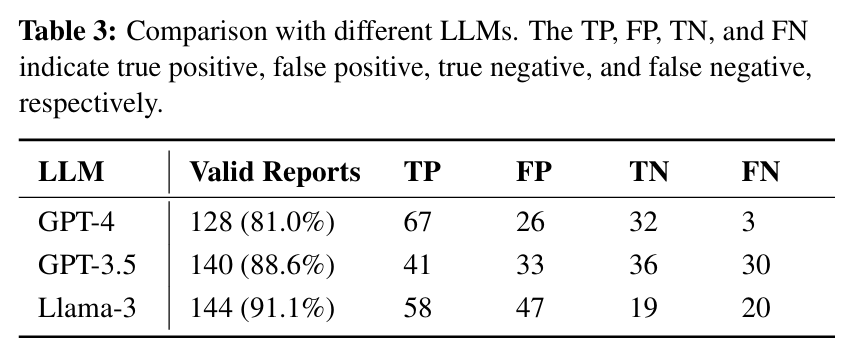
美中不足的是,作者没有给这么好的工具开源,让我们的Goshawk感觉有点孤单,所以给作者扣一分,敦促你们尽快开源(误):
G.O.S.S.I.P 推荐指数:accept
论文:https://www.usenix.org/system/files/usenixsecurity24-liu-dinghao-detecting.pdf
slides:https://www.usenix.org/system/files/usenixsecurity24_slides-liu-dinghao-detecting.pdf